> Europe is pouring more than €2 billion into sovereign cloud initiatives designed to reduce exposure to US legal reach.
(not Europe, the EU)
this is just sad. the US clouds did not happen because US poured billions into them. they happened because the financial/whatever situation was such that these businesses could happen.
now the EU, instead of making it easy for companies to innovate, spends billion on trying to catch up to the US. not even catching up. getting to where the US clouds are today.
the "skating to where the puck is going to be, not where it's been" quote comes to mind.
The clouds are not really american, but they are subject to american laws. The money and ownership needn't be american, anybody all around the world can buy stock in america companies. And the work to build these clouds was not done exclusively by americans, as all these companies have offices in europe to hire european engineers (to say nothing of the foreigners they pay to come live in america). From the perspective of the market, the clouds being american is an irrelevant detail, since they can reap whatever benefits they like of the world outside the US, as well as whatever benefits they want within the US.
I think this is an important thing to note in all these discussions of "why can't europe innovate": europeans in europe can and do innovate, but the processes to commercialize that innovation have been set up in the US, and have no market incentive to relocate or diversify. They can always take advantage of innovation wherever it lies.
To make the market care about something it is otherwise indifferent to, you have to pay it. Whereas capital markets ordinarily don't care if a company serving europeans is domiciled in the US, if you pay them a couple billion suddenly they will. It may be expensive, but it's the only solution to the problem at hand.
> now the EU, instead of making it easy for companies to innovate, spends billion on trying to catch up to the US. not even catching up. getting to where the US clouds are today.
What's your alternative? The US has behemoths with trillions of dollars in market cap, more than GDPs of most countries in EU. What kind of innovation in context of cloud do you think would allow anyone to compete with them? Who would risk their own money and pour billions into challenging them?
Isn't this essentially the Apple playbook typically? Don't innovate, let others find what works or not, then once you have something, catch up with the rest, try to out-compete? Apple is almost never "first" with something, but once they release something, it's a good iteration on that thing, I don't think Apple would be the only ones able to pull something like that off.
12,000 megawatts, equivalent to 12 large nuclear plants, of energy from its battery arrays.
but for how long is this battery array able to produce this amount of power? compared to the nuclear plant, where the answer is years.
watts are power, not energy. for example, a tea kettle might require 2kilowatts. this does not tell you how much does it cost you to use the tea kettle, because it does not tell you how long the tea kettle is consuming 2kilowatts.
sorry but this is not realistic. i looked at the [2] document and it's just a dream.
it's written in the style of "currently EU consumes this much energy, we project this to grow to that much until 2030/2040, we currently produce this much energy from renewables, so we need to multiply the amount of renewables with the correct number".
completely ignores the largest problem with solar/wind, storage. it just says that we should build enough storage. that's easy to say. i don't know of any country on this planet that made it work with purely solar/wind (please just tell me which one does, bonus point for one with a similar climate to europe), so it means we need to literally develop the technology (pls note, we do not even know what that technology will be) and then deploy it... in 6 years. that's completely unreal.
also, they recommend that we let the nuclear power generation go to zero, arguing for example, that nuclear-fuel needs to be imported into europe, but seems to be totally fine with importing in anything else (rare earth minerals etc.)
You are looking at individual countries. Europe has a transmission network, as well as battery storage, pumped storage, hydro generation, wind, solar and some nuclear. You keep adding renewables and storage, and keep retiring fossil generators. Europe has enough wind potential to power the entire world, for example. It's not impossible, it's math.
That doesn't help when you have a big storm, sunless/windless winter or any other combination of factors covering big area. Plus fragility of the supply, limitations of power lines and network, etc. As soon as you add more real life factors it doesn't look that promising. To have a potential doesn't imply to have a feasibility.
I have nothing agains further improving the network and load-balancing it smarter, but it's just in my interest to have some local duplication of energy generation. Or with my heatpump being out of service I may freeze or will have to buy a generator.
I don't disagree, fossil gas generators will be the last fossil generators to go (gas peakers and oil are already uneconomical compared to battery storage [1] [2] [3]). We're just arguing time horizon and deployment trajectories [4]. Certainly, don't tear down efficient fossil gas generators until they're no longer needed, but keep building renewables, storage, and transmission like our lives depend on it, because they do.
There has never been a one-hour window over the last 30 years where it hasn't been sunny or windy somewhere in Europe.
Obviously having all of Europe's electricity being generated on a single corner of Spain isn't feasible. But nobody is talking about 100% wind & solar. Hydro, storage, geothermal & nuclear can all add diversity and reliability. This can be modelled. We cannot get to 100% reliability but nothing can; local distribution SPOF bottlenecks limit reliability 99.99% regardless. And 99.99% is possible.
what about passwords that you have to type on websites? this solution does not protect you against phishing at all, right? (i mean, it does not help you with making sure the password is entered on the correct website)
so please make sure you understand the tradeoff, the risks involved.
by not having to trust youtube/twitter/instagram to not store what you do on their website, you instead have to trust a random browser extension to not store everything you do in your browser on every website.
(also, please do not use the it-is-open-source-you-can-read-the-source-code argument. no normal user is going to read and understand the whole source code, and repeat it for every update. at the end, you have to decide to trust it, or not)
i love the idea of uBlock Origin Lite. i am willing to trade some efficiency if i don't have to give it the "has access to everything i do in the browser" permissions.
Author here: I am daily driving a Purism Librem 5 currently (in order to write a proper review about it).
I have carried the PinePhone as a secondary device for a long time before, and I tried it as a main phone for a week twice (late 2020, April 2021) - things were too crashy for me back then (and the slowness admittedly annoyed me, too).
Many people do though. Personally, I've been using a Librem 5 as my daily driver for more than two years now and couldn't be happier despite of some quirks.
The main benefit of reproducible builds isn't security, but sanity. There is just no reason why your build process should produce different output for the same input. That just means it's broken in subtle ways and information is leaking into it that was never intended to be there.
The real benefit of reproducible builds however isn't for the individual software itself, but for the software landscape as a whole. As with reproducible builds you have the whole dependency chain specified completely from top to bottom, no more hidden dependencies. And everything is fully automated, not just on your personal machine, but in a way that others can reproduce. That in turn will dramatically improve the ease with which users can build software (and change it), as it turns an hour long hunt for dependencies into a single click.
To really see the fruits of this labor will still take some years, but it has the potential to pretty drastically reshape and improve the way FOSS software works (e.g. Nix Flakes) and actually allow users to make use of their freedom instead of giving up before they have even managed to build the software.
This blogpost can be summarized as with an XKCD essentially.
It positions itself with the following assertions:
> Q. If a user has chosen to trust a platform where all binaries must be codesigned by the vendor, but doesn’t trust the vendor, then reproducible builds allow them to verify the vendor isn’t malicious.
> I think this is a fantasy threat model. If the user does discover the vendor was malicious, what are they supposed to do? The malicious vendor can simply refuse to provide them with signed security updates instead, so this threat model doesn’t work.
Which only works in the context of proprietary vendors and not in the context of FOSS distributions. Nothing can be denied as everything is freely distributed. You want to have the ability to verify the work done by packagers and build servers.
Next up is the essentially the claim that "reproducible builds can't solve bugdoors. Thus it's insufficient to solve any problems".
Reproducible Builds is a nice property of any build system for multiple reasons. It's also part of the supply-chain security story and not the entire story alone. As for how much effort it is? It's a lot. But considering the core community of reproducible builds people is below 50 people, and we are still able to come close to an 88% reproducible builds in real world distributions should point out how achievable this goal is.
> Which only works in the context of proprietary vendors and not in the context of FOSS distributions. Nothing can be denied as everything is freely distributed. You want to have the ability to verify the work done by packagers and build servers.
Indeed. Open source isn't a vendor it's just volunteers from the Internet. If you look at the way people behave in nearly every other walk of life that isn't software, it would seem amazing that we somehow managed to create such a beautiful thriving gift economy. In order to keep it that way, we need to have reproducible builds, because they promote transparency.
It is however very very expensive. Even if you manage to surgically remove all the dependencies on things like __TIME__ then you still need to audit the code for things like iterating over hash tables. Many core libraries these days such as expat xml parsing will seed their data structures using /dev/random. You can qsort but you might get snagged by the fact that it doesn't use stable algorithms. If things don't work out then it helps to have deterministic execution too so you can run the build and see what it does differently that causes it to produce different output. Sadly, with things like kernel imposed memory randomization that's easier said than done.
So the unfortunate reality is that open source isn't arching towards determinism. The trend is very much the opposite where it's becoming more non-deterministic, especially in the last five years. So if having deterministic builds is something your org cares about then you really need to hire an expert and in many cases change the engineering culture too.
This is taken from the integration suite which Debian have been running for years. This represents checking out the code, and building twice. This is not distributed packages from Debian. This inflates the number a little bit.
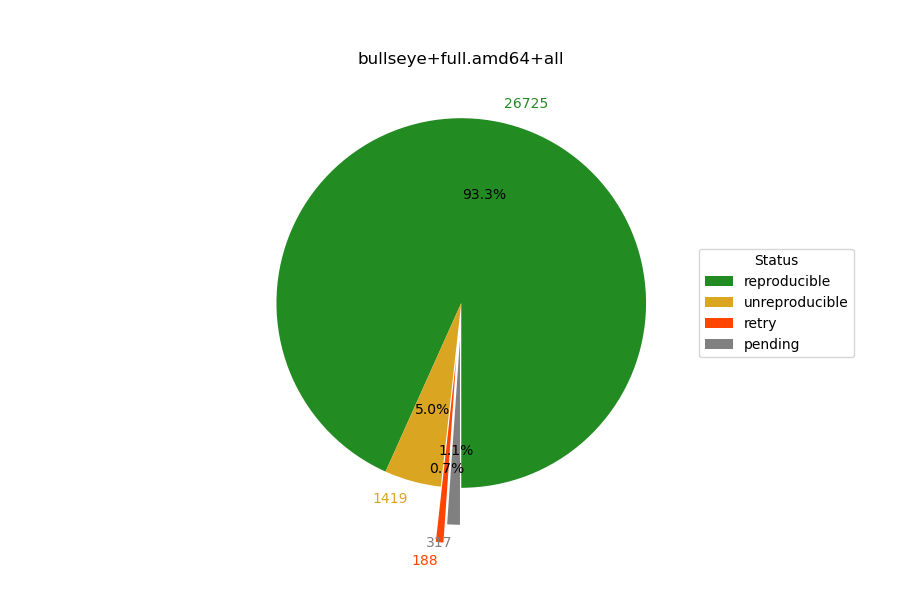
Why are 28.8% of Debian stable packages currently "pending"?
The stats on reproducible-builds.org say that "29595 packages (95.7%) successfully built reproducibly in bullseye/amd64."[0] which may not be accurate for the reasons given in the grandparent post, but I note that the situation seems to have improved significantly[1] since that mailing list thread.
>Why are 28.8% of Debian stable packages currently "pending"?
They are separate systems. The CI/CD and the rebuilder are not doing the same job essentially.
The 28.8% on pending might be because of slow rebuild times as the integration system has had more time building packages with significantly more CPU power behind it.
I guess the release date was as recent as 2021-07-23, and it's conceivable that such a rebuilding project being run only with spare CPU cycles might take months (or might only have started recently).
As an interesting data point, I see that the number of pending packages is now 21.2%. Let's hope that most of these remaining packages (and those being retried) turn out to be reproducible.
Such rebuilds systems are complicated and might not work 100% when you first start out. There can be multiple complete rebuilds done while removing edge-case bugs that either fails the building or introduces variance into the builds.
As a further analysis, I note that, excluding the current "pending" builds, the "reproducible" segment accounts for 93% of all packages so far.
I don't know if it's reasonable to assume that the "pending" packages are a representative sample in terms of their reproducibility, or how likely the "retry" packages are to succeed, but I'm hopeful that in a few days the "reproducible" stat will pass 90% for real.
{kind=link}
this is just sad. the US clouds did not happen because US poured billions into them. they happened because the financial/whatever situation was such that these businesses could happen.
now the EU, instead of making it easy for companies to innovate, spends billion on trying to catch up to the US. not even catching up. getting to where the US clouds are today.
the "skating to where the puck is going to be, not where it's been" quote comes to mind.